เฟรมเวิร์ก NVIDIA NeMo

ข้อมูลจำเพาะ
- ชื่อสินค้า: เฟรมเวิร์ก NVIDIA NeMo
- แพลตฟอร์มที่ได้รับผลกระทบ: วินโดวส์, ลินุกซ์, แมคโอเอส
- เวอร์ชันที่ได้รับผลกระทบ: ทุกเวอร์ชันก่อน 24
- ช่องโหว่ด้านความปลอดภัย: CVE-2025-23360
- คะแนนฐานการประเมินความเสี่ยง: 7.1 (CVSS เวอร์ชัน 3.1)
คำแนะนำการใช้ผลิตภัณฑ์
การติดตั้งการอัปเดตความปลอดภัย:
เพื่อปกป้องระบบของคุณ ให้ทำตามขั้นตอนเหล่านี้:
- ดาวน์โหลดเวอร์ชันล่าสุดจากหน้า NeMo-Framework-Launcher Releases บน GitHub
- ไปที่การรักษาความปลอดภัยผลิตภัณฑ์ NVIDIA เพื่อดูข้อมูลเพิ่มเติม
รายละเอียดการอัปเดตด้านความปลอดภัย:
การอัปเดตด้านความปลอดภัยจะแก้ไขช่องโหว่ใน NVIDIA NeMo Framework ซึ่งอาจนำไปสู่การทำงานของโค้ดและข้อมูลampering
อัพเกรดซอฟต์แวร์:
หากคุณใช้รุ่นสาขาก่อนหน้า ขอแนะนำให้อัพเกรดเป็นรุ่นสาขาล่าสุดเพื่อแก้ไขปัญหาด้านความปลอดภัย
เกินview
NVIDIA NeMo Framework เป็นกรอบงาน AI แบบสร้างสรรค์ที่ปรับขนาดได้และเป็นแบบคลาวด์ที่สร้างขึ้นสำหรับนักวิจัยและนักพัฒนาที่ทำงานเกี่ยวกับ แบบจำลองภาษาขนาดใหญ่, มัลติโมดัล และ การพูด AI (เช่น การจดจำเสียงพูดอัตโนมัติ และ การแปลงข้อความเป็นคำพูด) ช่วยให้ผู้ใช้สามารถสร้าง ปรับแต่ง และใช้งานโมเดล AI เชิงสร้างสรรค์ใหม่ๆ ได้อย่างมีประสิทธิภาพโดยใช้ประโยชน์จากโค้ดที่มีอยู่และจุดตรวจสอบโมเดลที่ได้รับการฝึกอบรมไว้ล่วงหน้า
คำแนะนำการตั้งค่า: ติดตั้ง NeMo Framework
NeMo Framework ให้การสนับสนุนครบวงจรสำหรับการพัฒนา Large Language Models (LLMs) และ Multimodal Models (MMs) โดยมอบความยืดหยุ่นในการใช้งานภายในองค์กร ในศูนย์ข้อมูล หรือกับผู้ให้บริการคลาวด์ที่คุณต้องการ นอกจากนี้ยังรองรับการทำงานบนสภาพแวดล้อมที่เปิดใช้งาน SLURM หรือ Kubernetes อีกด้วย

การดูแลข้อมูล
นีโมคิวเรเตอร์ [1] เป็นไลบรารี Python ที่ประกอบด้วยชุดโมดูลสำหรับการขุดข้อมูลและการสร้างข้อมูลสังเคราะห์ โมดูลเหล่านี้ปรับขนาดได้และปรับให้เหมาะสมสำหรับ GPU ทำให้เหมาะอย่างยิ่งสำหรับการรวบรวมข้อมูลภาษาธรรมชาติเพื่อฝึกอบรมหรือปรับแต่ง LLM ด้วย NeMo Curator คุณสามารถแยกข้อความคุณภาพสูงจากไฟล์ดิบจำนวนมากได้อย่างมีประสิทธิภาพ web แหล่งที่มาของข้อมูล
การฝึกอบรมและการปรับแต่ง
NeMo Framework มอบเครื่องมือสำหรับการฝึกอบรมและการปรับแต่งที่มีประสิทธิภาพ นิติศาสตร์มหาบัณฑิต (LLM) และโมเดลหลายโหมด รวมถึงการกำหนดค่าเริ่มต้นสำหรับการตั้งค่าคลัสเตอร์การคำนวณ การดาวน์โหลดข้อมูล และไฮเปอร์พารามิเตอร์ของโมเดล ซึ่งสามารถปรับแต่งเพื่อฝึกบนชุดข้อมูลและโมเดลใหม่ได้ นอกเหนือจากการฝึกเบื้องต้นแล้ว NeMo ยังรองรับเทคนิค Supervised Fine-Tuning (SFT) และ Parameter Efficient Fine-Tuning (PEFT) เช่น LoRA, Ptuning และอื่นๆ อีกมากมาย
มีสองตัวเลือกในการเริ่มการฝึกอบรมใน NeMo ได้แก่ การใช้อินเทอร์เฟซ NeMo 2.0 API หรือด้วย NeMo Run
- ด้วย NeMo Run (แนะนำ): NeMo Run มอบอินเทอร์เฟซสำหรับปรับปรุงการกำหนดค่า การดำเนินการ และการจัดการการทดลองในสภาพแวดล้อมการประมวลผลที่หลากหลาย ซึ่งรวมถึงการเปิดใช้งานงานบนเวิร์กสเตชันของคุณภายในเครื่องหรือบนคลัสเตอร์ขนาดใหญ่ ทั้งที่รองรับ SLURM หรือ Kubernetes ในสภาพแวดล้อมคลาวด์
- การฝึกอบรมเบื้องต้นและการเริ่มต้น PEFT อย่างรวดเร็วด้วย NeMo Run
- การใช้ NeMo 2.0 API: วิธีนี้ใช้ได้ดีกับการตั้งค่าแบบง่ายๆ ที่เกี่ยวข้องกับโมเดลขนาดเล็ก หรือหากคุณสนใจที่จะเขียนโปรแกรมโหลดข้อมูลแบบกำหนดเอง ลูปการฝึกอบรม หรือเปลี่ยนเลเยอร์โมเดล วิธีนี้ช่วยให้คุณมีความยืดหยุ่นและควบคุมการกำหนดค่าได้มากขึ้น และทำให้สามารถขยายและปรับแต่งการกำหนดค่าด้วยโปรแกรมได้อย่างง่ายดาย
-
ตราการเริ่มต้นใช้งานอย่างรวดเร็วด้วย NeMo 2.0 API
-
การย้ายจาก NeMo 1.0 ไปเป็น NeMo 2.0 API
-
การจัดตำแหน่ง
- นีโม-อะไลน์เนอร์ [1] เป็นชุดเครื่องมือที่ปรับขนาดได้สำหรับการปรับโมเดลให้มีประสิทธิภาพ ชุดเครื่องมือนี้รองรับอัลกอริทึมการปรับโมเดลที่ทันสมัย เช่น SteerLM, DPO, การเรียนรู้เสริมแรงจากข้อเสนอแนะของมนุษย์ (RLHF) และอื่นๆ อีกมากมาย อัลกอริทึมเหล่านี้ช่วยให้ผู้ใช้ปรับโมเดลภาษาให้ปลอดภัย ไม่เป็นอันตราย และเป็นประโยชน์มากขึ้น
- จุดตรวจสอบ NeMo-Aligner ทั้งหมดสามารถทำงานร่วมกันได้กับระบบนิเวศ NeMo ช่วยให้สามารถปรับแต่งและปรับใช้การอนุมานเพิ่มเติมได้
ขั้นตอนการทำงานแบบทีละขั้นตอนของทั้งสามเฟสของ RLHF บนโมเดล GPT-2B ขนาดเล็ก:
- การฝึกอบรม SFT
- การฝึกอบรมรูปแบบการให้รางวัล
- การฝึกอบรม PPO
นอกจากนี้ เรายังแสดงการสนับสนุนสำหรับวิธีการจัดตำแหน่งใหม่ๆ มากมาย:
- อ.ส.พ.:อัลกอริทึมการจัดตำแหน่งน้ำหนักเบาเมื่อเทียบกับ RLHF พร้อมด้วยฟังก์ชันการสูญเสียที่ง่ายกว่า
- การเล่นด้วยตนเอง การปรับแต่งอย่างละเอียด (SPIN)
- สตีร์LM: เทคนิคที่ใช้ SFT แบบมีเงื่อนไข พร้อมเอาต์พุตที่สามารถบังคับทิศทางได้
ตรวจสอบเอกสารเพื่อดูข้อมูลเพิ่มเติม: เอกสารการจัดตำแหน่ง
แบบจำลองหลายโหมด
- NeMo Framework มอบซอฟต์แวร์ที่เหมาะสมที่สุดสำหรับฝึกอบรมและใช้งานโมเดลมัลติโหมดล้ำสมัยในหลากหลายหมวดหมู่ เช่น โมเดลภาษามัลติโหมด รากฐานภาษาวิสัยทัศน์ โมเดลการแปลงข้อความเป็นรูปภาพ และโมเดล 2 มิติอื่นๆ โดยใช้ Neural Radiance Fields (NeRF)
- แต่ละหมวดหมู่ได้รับการออกแบบมาเพื่อตอบสนองความต้องการเฉพาะและความก้าวหน้าในสาขา โดยใช้โมเดลที่ล้ำสมัยเพื่อจัดการกับประเภทข้อมูลที่หลากหลาย รวมถึงข้อความ รูปภาพ และโมเดล 3 มิติ
บันทึก
เรากำลังย้ายการสนับสนุนสำหรับโมเดลมัลติโหมดจาก NeMo 1.0 ไปเป็น NeMo 2.0 หากคุณต้องการสำรวจโดเมนนี้ในระหว่างนี้ โปรดดูเอกสารสำหรับรุ่น NeMo 24.07 (ก่อนหน้า)
การปรับใช้และการอนุมาน
กรอบงาน NeMo นำเสนอเส้นทางต่างๆ สำหรับการอนุมาน LLM เพื่อรองรับสถานการณ์การปรับใช้และความต้องการด้านประสิทธิภาพที่แตกต่างกัน
ใช้งานกับ NVIDIA NIM
- NeMo Framework สามารถผสานรวมกับเครื่องมือปรับใช้โมเดลระดับองค์กรได้อย่างราบรื่นผ่าน NVIDIA NIM การผสานรวมนี้ขับเคลื่อนโดย NVIDIA TensorRT-LLM ช่วยให้มั่นใจได้ว่าการอนุมานจะได้รับการปรับให้เหมาะสมและปรับขนาดได้
- สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ NIM โปรดไปที่ NVIDIA webเว็บไซต์.
ปรับใช้ด้วย TensorRT-LLM หรือ vLLM
- NeMo Framework เสนอสคริปต์และ API สำหรับการส่งออกโมเดลไปยังไลบรารีที่ปรับให้เหมาะกับการอนุมานสองไลบรารี ได้แก่ TensorRT-LLM และ vLLM และเพื่อปรับใช้โมเดลที่ส่งออกกับ NVIDIA Triton Inference Server
- สำหรับสถานการณ์ที่ต้องมีการเพิ่มประสิทธิภาพ โมเดล NeMo สามารถใช้ประโยชน์จาก TensorRT-LLM ซึ่งเป็นไลบรารีเฉพาะสำหรับการเร่งความเร็วและเพิ่มประสิทธิภาพการอนุมาน LLM บน GPU NVIDIA กระบวนการนี้เกี่ยวข้องกับการแปลงโมเดล NeMo เป็นรูปแบบที่เข้ากันได้กับ TensorRT-LLM โดยใช้โมดูล nemo.export
- การปรับใช้ LLM เสร็จสิ้นแล้วview
- ปรับใช้ NeMo Large Language Models ด้วย NIM
- ปรับใช้ NeMo Large Language Models ด้วย TensorRT-LLM
- ปรับใช้ NeMo Large Language Models ด้วย vLLM
รุ่นที่รองรับ
แบบจำลองภาษาขนาดใหญ่
| แบบจำลองภาษาขนาดใหญ่ | การฝึกอบรมเบื้องต้นและ SFT | พีฟท์ | การจัดตำแหน่ง | การฝึกอบรม FP8 แบบบูรณาการ | TRT/TRTLLM | แปลงเป็น & จากการกอดใบหน้า | การประเมิน |
|---|---|---|---|---|---|---|---|
| ลามะ3 8B/70B, ลามะ3.1 405B | ใช่ | ใช่ | x | ใช่ (ตรวจสอบบางส่วนแล้ว) | ใช่ | ทั้งคู่ | ใช่ |
| มิกซ์ทรัล 8x7B/8x22B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | ใช่ | ทั้งคู่ | ใช่ |
| เนโมทรอน 3 8บี | ใช่ | x | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | ใช่ |
| เนโมทรอน 4 340บี | ใช่ | x | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | ใช่ |
| ไป๋ชวน2 7บี | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | ใช่ |
| แชทGLM3 6B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | ใช่ |
| เจมมา 2B/7B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | ใช่ | ทั้งคู่ | ใช่ |
| เจมม่า2 2B/9B/27B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | ใช่ |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | x | ใช่ |
| Phi3มินิ4k | x | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | ใช่ | ทั้งคู่ | ใช่ |
| สตาร์โคเดอร์ 15B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | ใช่ | ทั้งคู่ | ใช่ |
| สตาร์โคเดอร์2 3B/7B/15B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | ใช่ | ทั้งคู่ | ใช่ |
| เบิร์ต 110ม./340ม. | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | x |
| T5 220ม/3บ/11บ | ใช่ | ใช่ | x | x | x | x | x |
แบบจำลองภาษาวิสัยทัศน์
| แบบจำลองภาษาวิสัยทัศน์ | การฝึกอบรมเบื้องต้นและ SFT | พีฟท์ | การจัดตำแหน่ง | การฝึกอบรม FP8 แบบบูรณาการ | TRT/TRTLLM | แปลงเป็น & จากการกอดใบหน้า | การประเมิน |
|---|---|---|---|---|---|---|---|
| เนวีเอ (LLaVA 1.5) | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | จาก | x |
| ลามะ 3.2 วิสัยทัศน์ 11B/90B | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | จาก | x |
| LLaVA ต่อไป (LLaVA 1.6) | ใช่ | ใช่ | x | ใช่ (ไม่ได้รับการยืนยัน) | x | จาก | x |
การฝังโมเดล
| การฝังโมเดลภาษา | การฝึกอบรมเบื้องต้นและ SFT | พีฟท์ | การจัดตำแหน่ง | การฝึกอบรม FP8 แบบบูรณาการ | TRT/TRTLLM | แปลงเป็น & จากการกอดใบหน้า | การประเมิน |
|---|---|---|---|---|---|---|---|
| สเบิร์ต 340ม. | ใช่ | x | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | x |
| ลามะ 3.2 การฝัง 1B | ใช่ | x | x | ใช่ (ไม่ได้รับการยืนยัน) | x | ทั้งคู่ | x |
แบบจำลองมูลนิธิโลก
| แบบจำลองมูลนิธิโลก | หลังการฝึกอบรม | การอนุมานแบบเร่งรัด |
|---|---|---|
| จักรวาล-1.0-การแพร่กระจาย-ข้อความ2โลก-7B | ใช่ | ใช่ |
| จักรวาล-1.0-การแพร่กระจาย-ข้อความ2โลก-14B | ใช่ | ใช่ |
| คอสมอส-1.0-การแพร่กระจาย-วิดีโอ2โลก-7B | เร็วๆ นี้ | เร็วๆ นี้ |
| คอสมอส-1.0-การแพร่กระจาย-วิดีโอ2โลก-14B | เร็วๆ นี้ | เร็วๆ นี้ |
| คอสมอส-1.0-ออโตเรเกรสซีฟ-4B | ใช่ | ใช่ |
| คอสมอส-1.0-ออโตเรเกรสซีฟ-วิดีโอ2โลก-5B | เร็วๆ นี้ | เร็วๆ นี้ |
| คอสมอส-1.0-ออโตเรเกรสซีฟ-12B | ใช่ | ใช่ |
| คอสมอส-1.0-ออโตเรเกรสซีฟ-วิดีโอ2โลก-13B | เร็วๆ นี้ | เร็วๆ นี้ |
บันทึก
NeMo ยังรองรับการฝึกอบรมล่วงหน้าสำหรับสถาปัตยกรรมแบบแพร่กระจายและแบบถดถอยอัตโนมัติอีกด้วย text2world แบบจำลองรากฐาน
การพูด AI
การพัฒนาโมเดล AI เชิงสนทนาเป็นกระบวนการที่ซับซ้อนซึ่งเกี่ยวข้องกับการกำหนด สร้าง และฝึกอบรมโมเดลภายในโดเมนเฉพาะ กระบวนการนี้มักต้องทำซ้ำหลายรอบเพื่อให้ได้ระดับความแม่นยำสูง โดยมักต้องทำซ้ำหลายรอบเพื่อให้ได้ความแม่นยำสูง ปรับแต่งงานต่างๆ และข้อมูลเฉพาะโดเมน รับรองประสิทธิภาพการฝึกอบรม และเตรียมโมเดลสำหรับการใช้งานการอนุมาน
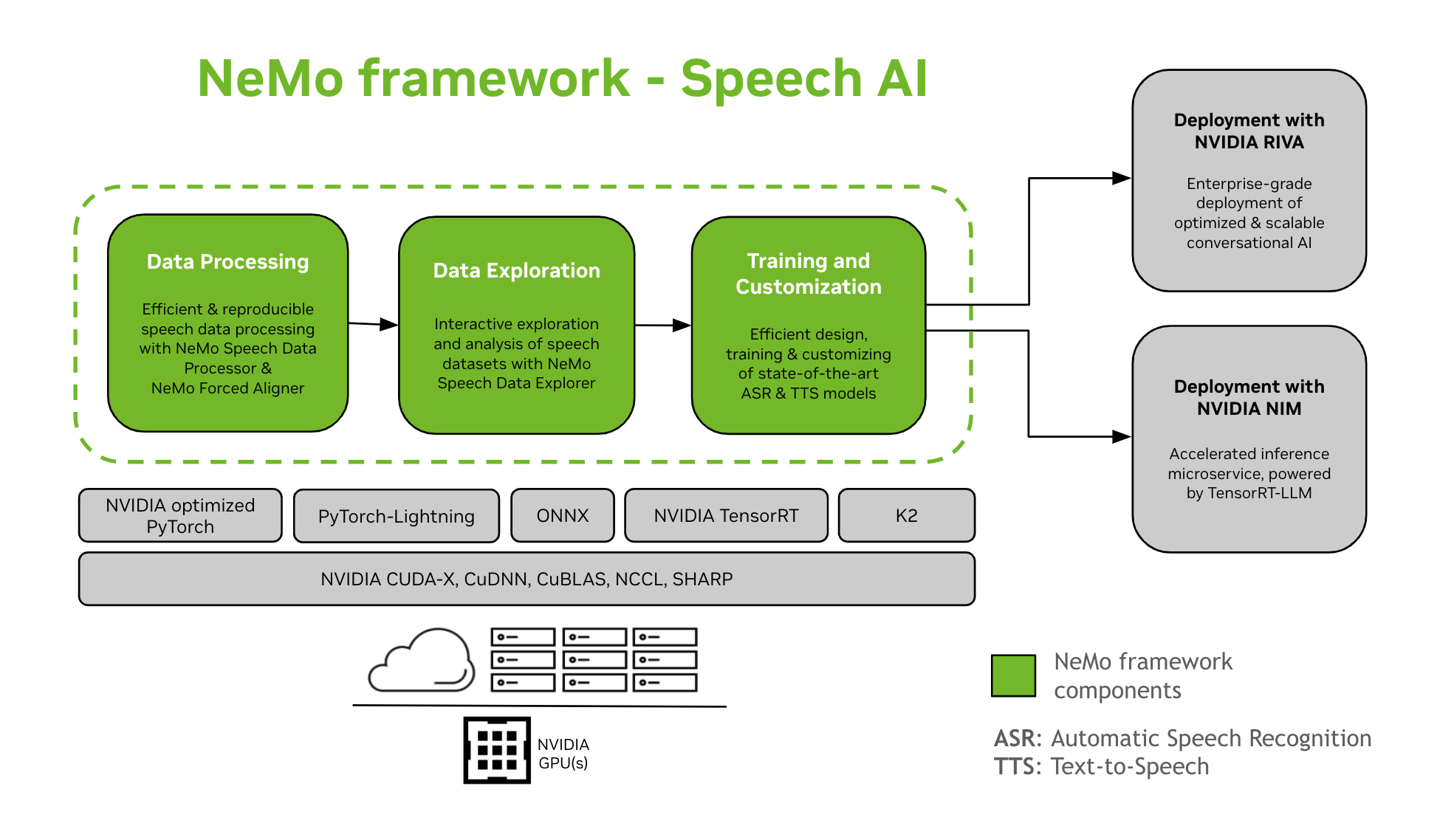
NeMo Framework ให้การสนับสนุนสำหรับการฝึกอบรมและปรับแต่งโมเดล Speech AI ซึ่งรวมถึงงานต่างๆ เช่น การจดจำเสียงพูดอัตโนมัติ (ASR) และการสังเคราะห์ข้อความเป็นเสียงพูด (TTS) นอกจากนี้ยังช่วยให้การเปลี่ยนผ่านไปสู่การใช้งานการผลิตระดับองค์กรด้วย NVIDIA Riva เป็นไปอย่างราบรื่น เพื่อช่วยเหลือผู้พัฒนาและนักวิจัย NeMo Framework จึงประกอบด้วยจุดตรวจสอบที่ผ่านการฝึกอบรมล่วงหน้าที่ทันสมัย เครื่องมือสำหรับการประมวลผลข้อมูลเสียงพูดที่ทำซ้ำได้ และคุณลักษณะสำหรับการสำรวจและวิเคราะห์ชุดข้อมูลเสียงพูดแบบโต้ตอบ ส่วนประกอบของ NeMo Framework สำหรับ Speech AI มีดังนี้:
การฝึกอบรมและการปรับแต่ง
NeMo Framework มีทุกสิ่งที่จำเป็นสำหรับการฝึกและปรับแต่งโมเดลการพูด (เอเอสอาร์, การจำแนกประเภทคำพูด, การจดจำผู้พูด, การเขียนไดอารี่สำหรับผู้พูด, และ ทีทีเอส) ในลักษณะที่สามารถทำซ้ำได้
โมเดลที่ผ่านการฝึกอบรมล่วงหน้าของ SOTA
- NeMo Framework นำเสนอสูตรล้ำสมัยและจุดตรวจสอบที่ผ่านการฝึกอบรมไว้ล่วงหน้าสำหรับหลายๆ เอเอสอาร์ และ ทีทีเอส แบบจำลองพร้อมคำแนะนำวิธีการโหลด
- เครื่องมือการพูด
- NeMo Framework นำเสนอชุดเครื่องมือที่เป็นประโยชน์สำหรับการพัฒนาโมเดล ASR และ TTS รวมถึง:
- เครื่องจัดตำแหน่งบังคับ NeMo (NFA) เพื่อสร้างเวลาระดับโทเค็น คำ และเซกเมนต์ampของเสียงพูดในเสียงโดยใช้โมเดลการจดจำเสียงพูดอัตโนมัติตาม CTC ของ NeMo
- โปรเซสเซอร์ข้อมูลเสียงพูด (SDP)ชุดเครื่องมือสำหรับการลดความซับซ้อนของการประมวลผลข้อมูลเสียง ช่วยให้คุณสามารถแสดงการดำเนินการประมวลผลข้อมูลใน config fileการลดขนาดโค้ดซ้ำซากให้เหลือน้อยที่สุดและอนุญาตให้ทำซ้ำและแชร์ได้
- โปรแกรมสำรวจข้อมูลเสียงพูด (SDE), แบบ Dash web แอปพลิเคชันสำหรับการสำรวจและวิเคราะห์ข้อมูลคำพูดแบบโต้ตอบ
- เครื่องมือสร้างชุดข้อมูล ซึ่งมีฟังก์ชันสำหรับปรับเสียงให้ยาว fileด้วยการถอดเสียงที่สอดคล้องกันและแบ่งออกเป็นส่วนสั้นๆ ที่เหมาะสำหรับการฝึกอบรมแบบจำลองการจดจำคำพูดอัตโนมัติ (ASR)
- เครื่องมือเปรียบเทียบ สำหรับโมเดล ASR เพื่อเปรียบเทียบการทำนายของโมเดล ASR ที่แตกต่างกันในระดับความแม่นยำของคำและการเปล่งเสียง
- โปรแกรมประเมิน ASR เพื่อประเมินประสิทธิภาพของโมเดล ASR และฟีเจอร์อื่นๆ เช่น การตรวจจับกิจกรรมเสียง
- เครื่องมือปรับข้อความให้เป็นมาตรฐาน เพื่อแปลงข้อความจากรูปแบบการเขียนเป็นรูปแบบการพูดและในทางกลับกัน (เช่น “วันที่ 31” เทียบกับ “วันที่ XNUMX”)
- เส้นทางสู่การใช้งาน
- โมเดล NeMo ที่ได้รับการฝึกอบรมหรือปรับแต่งโดยใช้ NeMo Framework สามารถปรับให้เหมาะสมและปรับใช้ด้วย NVIDIA Riva ได้ Riva จัดเตรียมคอนเทนเนอร์และแผนภูมิ Helm ที่ออกแบบมาโดยเฉพาะเพื่อทำให้ขั้นตอนต่างๆ สำหรับการใช้งานแบบกดปุ่มเป็นอัตโนมัติ
แหล่งข้อมูลอื่นๆ
- นีโม:ที่เก็บข้อมูลหลักสำหรับ NeMo Framework
- นีโม-วิ่ง:เครื่องมือสำหรับกำหนดค่า เปิดตัว และจัดการการทดลองการเรียนรู้ของเครื่องของคุณ
- นีโม-อะไลน์เนอร์: ชุดเครื่องมือที่ปรับขนาดได้สำหรับการจัดตำแหน่งโมเดลที่มีประสิทธิภาพ
- นีโมคิวเรเตอร์: ชุดเครื่องมือการประมวลผลและดูแลข้อมูลที่ปรับขนาดได้สำหรับ LLM
มีส่วนร่วมกับชุมชน NeMo ถามคำถาม รับการสนับสนุน หรือรายงานจุดบกพร่อง
- การสนทนาเรื่อง NeMo
- ประเด็นเรื่องนีโม
ภาษาการเขียนโปรแกรมและเฟรมเวิร์ก
- งูหลาม:อินเทอร์เฟซหลักในการใช้ NeMo Framework
- ไพทอร์ช:NeMo Framework ถูกสร้างขึ้นบน PyTorch
ใบอนุญาต
- ที่เก็บข้อมูล Github ของ NeMo ได้รับอนุญาตภายใต้ใบอนุญาต Apache 2.0
- NeMo Framework ได้รับอนุญาตภายใต้ข้อตกลงผลิตภัณฑ์ NVIDIA AI การดึงและใช้คอนเทนเนอร์แสดงว่าคุณยอมรับข้อกำหนดและเงื่อนไขของใบอนุญาตนี้
- คอนเทนเนอร์ NeMo Framework ประกอบด้วยสื่อ Llama ที่ควบคุมโดยข้อตกลงอนุญาตสิทธิ์ชุมชน Meta Llama3
เชิงอรรถ
ขณะนี้การรองรับ NeMo Curator และ NeMo Aligner สำหรับโมเดล Multimodal อยู่ในระหว่างดำเนินการและจะพร้อมให้บริการเร็วๆ นี้
คำถามที่พบบ่อย
ถาม: ฉันจะตรวจสอบได้อย่างไรว่าระบบของฉันได้รับผลกระทบจากช่องโหว่นี้หรือไม่?
A: คุณสามารถตรวจสอบว่าระบบของคุณได้รับผลกระทบหรือไม่โดยตรวจสอบเวอร์ชันของ NVIDIA NeMo Framework ที่ติดตั้ง หากเป็นเวอร์ชันต่ำกว่า 24 ระบบของคุณอาจมีความเสี่ยง
ถาม: ใครเป็นผู้รายงานปัญหาความปลอดภัย CVE-2025-23360?
A: ปัญหาด้านความปลอดภัยได้รับการรายงานโดย Or Peles – JFrog Security NVIDIA ยอมรับถึงการมีส่วนร่วมของพวกเขา
ถาม: ฉันจะรับการแจ้งเตือนข่าวสารด้านความปลอดภัยในอนาคตได้อย่างไร
ตอบ: ไปที่หน้าความปลอดภัยของผลิตภัณฑ์ NVIDIA เพื่อสมัครรับการแจ้งเตือนข่าวสารด้านความปลอดภัย และติดตามข้อมูลเกี่ยวกับการอัปเดตด้านความปลอดภัยของผลิตภัณฑ์
เอกสาร / แหล่งข้อมูล
 |
เฟรมเวิร์ก NVIDIA NeMo [พีดีเอฟ] คู่มือการใช้งาน เฟรมเวิร์ก NeMo, นีโม, เฟรมเวิร์ก |